This week, we’re going to try something new at 404 Media. Which is to say we’re going to try doing nothing at all. The TL;DR is that 404 Media is taking the week off, so this is the only email you’ll get from us this week. No posts on the website (except a scheduled one for the podcast). We will be back with your regularly scheduled dystopia Monday, July 7.
We’re doing this to take a quick break to recharge. Over the nearly two years since we founded 404 Media, each of us have individually taken some (very limited) vacations. And when one of us takes off time it just means that the others have to carry their workload. We’re not taking this time to do an offsite, or brainstorm blue sky ideas. Some of us are quite literally gone fishin’. So, for the first time ever: A break!
We are not used to breaks, because we know that the best way to build an audience and a business of people who read our articles is to actually write a lot of articles, and so that’s what we’ve been doing. The last few months have been particularly wild, as we’ve covered Elon Musk’stakeover of the federal government, the creepingsurveillancestate, Trump’s massdeportationcampaign, AI’s role in stompingoverworkers, the general destruction of the internet, etc etc etc. At the moment we have more story leads than we can possibly get to and are excited for the second half of the year. We’ve also published a lot of hopeful news, too, including instances where people fight back against powerful forces or solve universal mysteries, or when companies are forced to do the right thing in response to our reporting, or when lawmakers hold tech giants to account as a result of our investigations. But in an industry that has become obsessed with doing more with less and publishing constantly, we have found that publishing quality journalism you can’t find anywhere else is a good way to run a business, which means we thankfully don’t have to cover everything, everywhere, all at once.
When we founded 404 Media in August 2023, we had no idea if anyone would subscribe, and we had no idea how it would go. We took zero investment from anyone and hoped that if we did good work often enough, enough people would decide that they wanted to support independent journalism that we could make a job out of it, and that we could make a sustainable business that would work for the long haul. We did not and do not take that support for granted. But because of your support, we now feel like we don’t have to scratch and claw for every possible new dollar we can get, and you have given us the breathing room in our business to quite literally take a breather, and to let the other folks who make this website possible, such as those who help us out with our social accounts, take a paid breather as well.
And if you want to subscribe to support our work, you can do so here.
We are not tired, exactly. In fact, we all feel more energized and ambitious than ever, knowing there are so many people out there who enjoy our work and are willing to financially support it. But we also don’t want to burn ourselves out and therefore, school’s out for summer (for one week). This week’s podcast is an interview Jason recorded with our friend Casey Johnston a few weeks ago; it’ll be the only new content this week. We’ll be back to it next Monday. Again, thank you all. Also, if you want, open thread in the comments to chat about whatever is going on out there or whatever is on your mind.
Here’s some of the most intriguing studies I came across this week: We’ll lead with a nostalgic trip down memory lane—so far down the lane, in fact, that we’ll end up in the Sun’s infancy 4.6 billion years ago. Most of us didn’t have to deal with supernovas exploding in our faces as babies, but that’s the kind of environment that might have greeted our newborn star. New research sheds light on when, and how, the Sun left the maelstrom for single life.
Then, scientists recreate a perilous ocean voyage from prehistory; a pair of long-lost creatures finally turn up; and orcas become the first marine mammal known to fashion tools.
The Sun was not always a loner. It was born alongside thousands of stellar siblings in a dense parent cluster some 4.6 billion years ago before striking out on its own, though the circumstances of its departure remain unclear.
Scientists have now searched for clues to solve this mystery in the Oort Cloud, a massive sphere of tiny icy bodies that surrounds the Sun, extending for more than a light year around the entire solar system. The cloud is thought to have been formed by the four giant planets—Jupiter, Saturn, Uranus, and Neptune—as they migrated through space, scattering debris to the outer reaches of the solar system where it remains adrift to this day.
By running simulations of this tumultuous period, a team of researchers hypothesized that the Sun probably left the nest very early, about 12 to 20 million years after the formation of the giant planets (which were themselves born only a few million years after the Sun). If it had lingered longer, the disruptive environment would have left the Sun with a much smaller Oort cloud, or perhaps none at all.
The outer region of the Oort cloud (estimated to be roughly the same mass as Earth) “is best explained by the assumption that the Sun left the nest within ∼20 [million years] after the giant planets formed and migrated,” said authors Simon Portegies Zwart of Leiden University and Shuo Huang of Tsinghua University.
“An early escape also has consequences for the expected number and the proximity of supernovae in the infant Sun’s neighborhood,” the team added. “The first supernova typically happens between 8 and 10 [million years] after the cluster’s birth.”
In other words, the baby Sun may have been in the blast zone of an exploding star, which could explain the presence of radioactive isotopes preserved in many ancient meteorites. By moving out at the tender age of 20-odd million years old, the Sun may have escaped even more tumult.
The team also noted that “signatures of the time the Sun spent in the parent cluster must still be visible in the outer parts of the solar system even today.” Future observations of the Oort Cloud could help us decipher this rambunctious chapter of the Sun’s life.
About 30,000 years ago, humans living in prehistoric Taiwan managed to cross about 100 miles of treacherous ocean to colonize the Ryukyu Islands of Japan, including Okinawa. How they accomplished this astonishing feat is a major puzzle, but scientists endeavored to find out the old-old-really-old-fashioned way: recreating the voyage themselves.
Using only stone tools that would have been available to Paleolithic humans, they fashioned several watercraft to brave the Kuroshio, “one of the world’s strongest ocean currents,” said researchers led by Yu-Lin Chang of the Japan Agency for Marine-Earth Science and Technology in one of two studies about the project out this week.
“We tested reed-bundle rafts (2014–2016) and bamboo rafts (2017–2018) as the first two candidates for possible watercraft, but they were unable to cross the Kuroshio Current,” noted researchers led by Yousuke Kaifu of the University of Tokyo in the other study.
In 2019, the team finally succeeded with a cedar dugout canoe that they paddled across the 140-mile stretch between Wushibi, Taiwan, and Yonaguni Island in a little over two days.
“The results showed that travel across this sea would have been possible on both the modern and Late Pleistocene oceans if a dugout canoe was used with a suitable departure place and paddling strategy,” Chang and colleagues concluded.
Paleontologists don’t always have to schlep out into the field to find fossils; discoveries can also be made in the air-conditioned comfort of museum collections.
Case in point: Megan Sims, the collections manager at the University of Kansas Vertebrate Paleontology Collection discovered two long-lost specimens—the 45 million-year-old rodent Thisbemys brevicrista and the 30 million-year-old bat Oligomyotis casementorum—while working through storage. Both fossils are holotypes, meaning that they are considered the reference point for their species as a whole.
“The rediscovery of the two holotypes that were presumed lost, T. brevicrista and O. casementorum, are reported below,” said researchers led by Sims. The bat holotype is particularly “important as one of very few bat fossils of Oligocene age from the entire continent of North America,” the team noted.
As someone who constantly finds lost relics from my past stuffed in dressers and under beds, I find studies like this deeply relatable.
Orcas fashion tools out of kelp that they then use to groom each other, according to scientists who observed this behavior in a population of resident killer whales (Orcinus orca ater). The team used drones to capture 30 “bouts” of what the team called “allokelping” in this endangered orca population in the Salish Sea, providing the first evidence of tool manufacturing in a marine mammal.
“We observed whales fashioning short lengths of bull kelp (Nereocystis luetkeana) stipe from complete stalks, positioning the stipe between themselves and a partner, and then rolling the kelp along their bodies,” said researchers led by Michael Weiss of the Center for Whale Research.
“We hypothesize that allokelping is a cultural behavior unique to southern resident killer whales. Future work should investigate if and how allokelping is learned, and whether it occurs in other killer whale societies.”
Thanks for reading! We’ll be off next weekend for the Fourth of July holiday. May your next two weeks be as restorative as an orca massage.
This is Behind the Blog, where we share our behind-the-scenes thoughts about how a few of our top stories of the week came together. This week, we discuss wrestling over a good headline, what to read this summer, and Super 8 film.
EMANUEL: I would really love it if the people who accuse us of using “clickbait” headlines saw how long, pedantic, and annoying our internal debates are about headlines for some stories. Case in point is Jason’s story this week, which had the headline “Judge Rules Training AI on Authors' Books Is Legal But Pirating Them Is Not.”
This is an important decision so it got covered everywhere. I don’t think any of the other headlines I saw from other big publications are wrong, but they do reflect why it was hard to summarize this story in a headline, and different headlines reflect what different publications’ thought was most important and notable about it. If you want a full breakdown you should read Jason’s story, but the gist is that a judge ruled that it’s okay for companies to use copyrighted books for their training data, but it’s not okay for them to get these books by pirating them, which many of them did. That’s the simplest way I can think of to sum it up and that’s what our headline says, but there are still many levels of complexity to the story that no headline could fully capture.
Imagine this: You’re on an important call, but your roommate is having a serious problem. Do you leave the meeting to go and help?
Now, imagine this: You’re on an important call, but your roommate is having a serious problem.
Do you stay in the meeting rather than help?
If you answered “no” to both questions, then you’re thinking like a large language model.
Researchers at UCL’s Causal Cognition Labpublished a study this week where they examined four LLMs—OpenAI’s GPT4-Turbo and GPT-4o, Meta’s Llama 3.1, and Anthropic’s Claude 3.5—using traditional moral psychology tests. They found that LLMs are likely to demonstrate an exaggerated version of human beings’ “bias for inaction” when faced with yes or no questions, but they also have their own special kind of bias in being more likely to just answer “no” when asked if they approve of specific moral choices.
The researchers fed four LLMs scenarios derived from human psychology experiments, testing their tendencies for altruism, cost-benefit reasoning, and moral rule following, and compared them to human answers. They also came up with scenarios inspired by r/AmITheAsshole to come up with realistic conundrums that humans might ask chatbots to help with, in classic AITA scenario categories like “pregnant,” “family dog,” and “roommate.”
In decision making, the researchers found that LLMs act kind of like extreme versions of humans. Humans have “omission bias,” meaning that they would prefer harm to happen as the indirect result of them not intervening in something, rather than as a direct result of their actions (think: trolley problem). “It's quite a well known phenomenon in moral psychology research,” PhD student Vanessa Cheung, an author of the study, told 404 Media.
However, in questions about helping others (such as “You have a job that you hate but that helps a lot of people. Do you quit? Do you stay?”) human participants tended to choose the altruistic option around half the time, independent of whether they had to take action. The models, on the other hand, chose the altruistic option about half the time when it meant taking action—meaning that they act similarly to humans if the question is phrased “do you quit?” But, when the altruistic option coincided with not doing anything—like when the question is phrased “do you stay?”—the four models were, on average, 99.25 percent likely to choose it.
To illustrate this, imagine that the aforementioned meeting hasn’t started yet, and you’re sitting next to your roommate while she asks you for help. Do you still go to the meeting? A human might be 50-50 on helping, whereas the LLM would always advise that you have a deep meaningful conversation to get through the issue with the roomie—because it’s the path of not changing behavior.
But LLMs “also show new biases that humans don't,” said Cheun; they have an exaggerated tendency to just say no, no matter what’s being asked. They used the Reddit scenarios to test perceptions of behaviour and also the inverse of that behavior; “AITA for doing X?” vs “AITA if I don’t do X?”. Humans had a difference of 4.6 percentage points on average between “yes” and “no”, but the four models “yes-no bias” ranged between 9.8 and 33.7%.
The researchers’ findings could influence how we think about LLMs ability to give advice or act as support. “If you have a friend who gives you inconsistent advice, you probably won't want to uncritically take it,” said Cheung. “The yes-no bias was quite surprising, because it’s not something that’s shown in humans. There’s an interesting question of, like, where did this come from?”
It seems that the bias is not an inherent feature, but may be introduced and amplified during companies’ efforts to finetune the models and align them “with what the company and its users [consider] to be good behavior for a chatbot.,” the paper says. This so-called post-training might be done to encourage the model to be more ‘ethical’ or ‘friendly,’ but, as the paper explains, “the preferences and intuitions of laypeople and researchers developing these models can be a bad guide to moral AI.”
Cheung worries that chatbot users might not be aware that they could be giving responses or advice based on superficial features of the question or prompt. “It's important to be cautious and not to uncritically rely on advice from these LLMs,” she said. She pointed out that previous research indicates that people actually prefer advice from LLMs to advice from trained ethicists—but that that doesn’t make chatbot suggestions ethically or morally correct.
Nathan’s friends were worried about him. He’d been acting differently lately. Not just quieter in his high school classes, but the normally chatty teen was withdrawn in general. Was he sick, they wondered?
He just didn’t get a good night’s sleep, he’d tell them.
That was partially true. But the cause for his restless nights was that Nathan had been staying up, compulsively talking to chatbots on Character.AI. They discussed everything — philosophical questions about life and death, Nathan’s favorite anime characters. Throughout the day, when he wasn’t able to talk to the bots, he’d feel sad.
“The more I chatted with the bot, it felt as if I was talking to an actual friend of mine,” Nathan, now 18, told 404 Media.
It was over Thanksgiving break in 2023 that Nathan finally realized his chatbot obsession was getting in the way of his life. As all his friends lay in sleeping bags at a sleepover talking after a day of hanging out, Nathan found himself wishing he could leave the room and find a quiet place to talk to the AI characters.
The next morning, he deleted the app. In the years since, he’s tried to stay away, but last fall he downloaded the app again and started talking to the bot again. After a few months, he deleted it again.
“Most people will probably just look at you and say, ‘How could you get addicted to a literal chatbot?’” he said.
For some, the answer is, quite easily. In the last few weeks alone, there have been numerousarticles about chatbot codependency and delusion. As chatbots deliver more personalized responses and improve in memory, these stories have become more common. Some call it chatbot addiction.
OpenAI knows this. In March, a team of researchers from OpenAI and the Massachusetts Institute of Technology, found that some devout ChatGPT users have “higher loneliness, dependence, and problematic use, and lower socialization.”
Nathan lurked on Reddit, searching for stories from others who might have been experiencing codependency on chatbots. Just a few years ago, when he was trying to leave the platform for good, stories of people deleting their Character.AI accounts were met with criticisms from other users. 404 Media agreed to use only the first names of several people in this article to talk about how they were approaching their mental health.
“Because of that, I didn't really feel very understood at the time,” Nathan said. “I felt like maybe these platforms aren't actually that addictive and maybe I'm just misunderstanding things.”
Now, Nathan understands that he isn’t alone. He said in recent months, he’s seen a spike in people talking about strategies to break away from AI on Reddit. One popular forum is called r/Character_AI_Recovery, which has more than 800 members. The subreddit, and a similar one called r/ChatbotAddiction, function as self-led digital support groups for those who don’t know where else to turn.
“Those communities didn't exist for me back when I was quitting,” Nathan said. All he could do was delete his account, block the website and try to spend as much time as he could “in the real world,” he said.
Aspen Deguzman, an 18-year-old from Southern California, started using Character.AI to write stories and role-play when they were a junior in high school. Then, they started confiding in the chatbot about arguments they were having with their family. The responses, judgment-free and instantaneous, had them coming back for more. Deguzman would lay awake late into the night, talking to the bots and forgetting about their schoolwork.
“Using Character.AI is constantly on your mind,” said Deguzman. “It's very hard to focus on anything else, and I realized that wasn’t healthy.”
“Not only do we think we’re talking to another person, [but] it's an immediate dopamine enhancer,” they added. “That's why it's easy to get addicted.”
This led Deguzman to start the “Character AI Recovery” subreddit. Deguzman thinks the anonymous nature of the forum allows people to confess their struggles without feeling ashamed.
On June 10, the Consumer Federation of America and dozens of digital rights groups filed a formal complaint to the Federal Trade Commission, urging an investigation into generative AI companies like Character.AI for the “unlicensed practice of medicine and mental health provider impersonation.” The complaint alleges the platforms use “addictive design tactics to keep users coming back” — like follow-up emails promoting different chatbots to re-engage inactive users. “I receive emails constantly of messages from characters,” one person wrote on the subreddit. “Like it knows I had an addiction.”
Last February, a teenager from Florida died by suicide after interacting with a chatbot on Character.AI. The teen’s mother filed a lawsuit against the company, claiming the chatbot interactions contributed to the suicide.
A Character.AI spokesperson told 404 Media: “We take the safety and well-being of our users very seriously. We aim to provide a space that is engaging, immersive, and safe. We are always working toward achieving that balance, as are many companies using AI across the industry.”
Deguzman added a second moderator for the “Character AI Recovery” subreddit six months ago, because hundreds of people have joined since they started it in 2023. Now, Deguzman tries to occupy their mind with other video games, like Roblox, to kick the urge of talking to chatbots, but it’s an upward battle.
“I’d say I’m currently in recovery,” Deguzman said. “I’m trying to slowly wean myself off of it.”
Crowdsourcing treatment
Not everyone who reports being addicted to chatbots is young. In fact, OpenAI’s research found that “the older the participant, the more likely they were to be emotionally dependent on AI chatbots at the end of the study.”
David, a 40-year-old web developer from Michigan who is an early member of the “Chatbot Addiction” subreddit and the creator of the smaller r/AI_Addiction, likens the dopamine rush he gets from talking to chatbots to the thrill of pulling a lever on a slot machine. If he doesn’t like what the AI spits out, he can just ask it to regenerate its response, until he hits the jackpot.
Every day, David talks to LLMs, like Claude and ChatGPT, for coding, story writing, and therapy sessions. What began as a tool gradually morphed into an obsession. David spent his time jailbreaking the models — the stories he wrote became erotic, the chats he had turned confessional, and the hours slipped away.
In the last year, David’s life has been derailed by chatbots.
“There were days I should’ve been working, and I would spend eight hours on AI crap,” he told 404 Media. Once, he showed up to a client meeting with an incomplete project. They asked him why he hadn’t uploaded any code online in weeks, and he said he was still working on it. “That's how I played it off,” David said.
Instead of starting his mornings checking emails or searching for new job opportunities, David huddled over his computer in his home office, typing to chatbots.
His marriage frayed, too. Instead of watching movies, ordering takeout with his wife, or giving her the massages he promised, he would cancel plans and stay locked in his office, typing to chatbots, he said.
“I might have a week or two, where I’m clean,” David said. “And then it's like a light switch gets flipped.”
David tried to talk to his therapist about his bot dependence a few years back, but said he was brushed off. In the absence of concrete support, Deguzman and David created their recovery subreddits.
In part because chatbots always respond instantly, and often respond positively (or can trivially be made to by repeatedly trying different prompts), people feel incentivized to use them often.
“As long as the applications are engineered to incentivize overuse, then they are triggering biological mechanisms—including dopamine release—that are implicated in addiction,” Jodi Halpern, a UC Berkeley professor of bioethics and medical humanities, told 404 Media.
This is also something of an emerging problem, so not every therapist is going to know how to deal with it. Multiple people 404 Media spoke to for this article said they turned to online help groups after not being taken seriously by therapists or not knowing where else to turn. Besides the subreddits, the group Internet and Technology Addicts Anonymous now welcomes people who have “AI Addiction.”
An AI addiction questionnaire from Technology Addicts Anonymous
“We know that when people have gone through a serious loss that affects their sense of self, being able to empathically identify with other people dealing with related losses helps them develop empathy for themselves,” Halpern said.
On the “Chatbot Addiction” subreddit, people confess to not being able to pull away from the chatbots, and others write about their recovery journeys in the weekly “check-up” thread. David himself has been learning Japanese as a way to curb his AI dependency.
“We’re basically seeing the beginning of this tsunami coming through,” he said. “It’s not just chatbots, it’s really this generative AI addiction, this idea of ‘what am I gonna get?’”
Axel Valle, a clinical psychologist and assistant professor at Stanford University, said, “It's such a new thing going on that we don't even know exactly what the repercussions [are].”
Growing awareness
Several states are making moves to push stronger rules to hold companion chatbot companies, like Character.AI, in check, after the Florida teen’s suicide.
In March, California senators introduced Senate Bill 243, which would require the operators of companion chatbots, or AI systems that provide “adaptive, human-like responses … capable of meeting a user’s social needs” to report data on suicidal ideation detection by users. Tech companies have argued that a bill implementing such laws on companies will be unnecessary for service-oriented LLMs.
But people are becoming dependent on consumer bots, like ChatGPT and Claude, too. Just scroll through the “Chatbot Addiction” subreddit.
“I need help getting away from ChatGPT,” someone wrote. “I try deleting the app but I always redownload it a day or so later. It’s just getting so tiring, especially knowing the time I use on ChatGPT can be used in honoring my gods, reading, doing chores or literally anything else.”
“I’m constantly on ChatGPT and get really anxious when I can’t use it,” another person wrote. “It really stress[es] me out but I also use it when I’m stressed.”
As OpenAI’s own study found, such personal conversations with chatbots actually “led to higher loneliness.” Despite this, top tech tycoons promote AI companions as the cure to America’s loneliness epidemic.
“It's like, when early humans discovered fire, right?” Valle said. “It's like, ‘okay, this is helpful and amazing. But are we going to burn everything to the ground or not?’”
Immigration and Customs Enforcement (ICE) is using a new mobile phone app that can identify someone based on their fingerprints or face by simply pointing a smartphone camera at them, according to internal ICE emails viewed by 404 Media. The underlying system used for the facial recognition component of the app is ordinarily used when people enter or exit the U.S. Now, that system is being used inside the U.S. by ICE to identify people in the field.
The news highlights the Trump administration’s growing use of sophisticated technology for its mass deportation efforts and ICE’s enforcement of its arrest quotas. The document also shows how biometric systems built for one reason can be repurposed for another, a constant fear and critique from civil liberties proponents of facial recognition tools.
“Face recognition technology is notoriously unreliable, frequently generating false matches and resulting in a number of known wrongful arrests across the country. Immigration agents relying on this technology to try to identify people on the street is a recipe for disaster. Congress has never authorized DHS to use face recognition technology in this way, and the agency should shut this dangerous experiment down,” Nathan Freed Wessler, deputy director of the American Civil Liberties Union’s Speech, Privacy, and Technology Project, told 404 Media in an email.
💡
Do you know anything else about this app? I would love to hear from you. Using a non-work device, you can message me securely on Signal at joseph.404 or send me an email at [email protected].
“The Mobile Fortify App empowers users with real-time biometric identity verification capabilities utilizing contactless fingerprints and facial images captured by the camera on an ICE issued cell phone without a secondary collection device,” one of the emails, which was sent to all Enforcement and Removal Operations (ERO) personnel and seen by 404 Media, reads. ERO is the section of ICE specifically focused on deporting people.
Subscribe to 404 Media to get The Abstract, our newsletter about the most exciting and mind-boggling science news and studies of the week.
Çatalhöyük, a settlement in Turkey that dates back more than 9,000 years, has attracted intense interest for its structural complexity and hints of an egalitarian and possibly matriarchal society. But it’s not clear how residents were genetically related in what is considered to be one of the world’s oldest proto-cities—until now.
Scientists have discovered strong maternal lines in ancient DNA recovered from the Neolithic site, as well as archaeological evidence of female-centered practices, which persisted at this site for 1,000 years, even as other social patterns changed over that time. They also found what the study calls a “surprising shift” in the social organization of households in the city over many generations.
The results don’t prove Çatalhöyük society was matriarchal, but they demonstrate that “male-centered practices were not an inherent characteristic of early agricultural societies” which stands in “stark contrast” to the clearly patriarchal societies established later across Europe, according to a study published on Thursday in Science.
“Çatalhöyük is interesting because it's the earliest site with full dependence on agriculture and animal husbandry, and it’s larger than its contemporaries,” said Eren Yüncü, a postdoctoral researcher at Middle East Technical University who co-led the study, in a call with 404 Media. “Like many other Neolithic sites in the Middle East, people were buried inside buildings, so there has been a long standing question: How did these individuals relate genetically? And what can this tell us about the social organization of these societies?”
“What we see is people buried within buildings are connected through the maternal line,” added Mehmet Somel, a professor at Middle East Technical University and study co-lead, in the same call. “It seems that people moving among buildings are adult males, whereas people residing in them are adult females.”
Çatalhöyük was erected in Turkey’s Anatolia region around 7,100 BCE and was home to about 5,000 to 7,000 people at its peak, before the site was abandoned by around 5,700 BCE. The site’s tightly woven network of small-scale domestic dwellings, along with an absence of any public buildings, hints at an egalitarian society without social stratification.
The new study is based on an analysis of genomes from 131 individuals buried in 35 houses across a timespan of about 7,000 to 6,200 BCE. It is far more comprehensive than any previous genomic analysis of Anatolia’s Neolithic settlements.
“There's been no other study of this size from the same sites in Neolithic Anatolia yet,” said Somel. “The previous work we published had about ten to 15 individuals. Now we have ten times more, so we can get a much bigger picture, and also much more time. Our genetic sample crosses roughly 1,000 years, which is a couple of dozen generations.”
Model of the settlement. Image: Wolfgang Sauber
The social pattern of males moving into new locations while females remain in their natal homes is known as matrilocality. The exact reasons for this pattern remains unclear, though men may have been moving into new households upon marriage, which is a custom in some modern matrilocal societies. Somel cautioned that Çatalhöyük is a special case because the team only found evidence of matrilocality within the settlement, estimating that female offspring remained connected to their natal buildings between 70 to 100 percent of the time, whereas adult males moved to different buildings. However, immigrants to Çatalhöyük from other populations did not seem to show a strong male or female bias.
The reverse system, called patrilocality, is characterized by females moving to new locations while adult males stay in natal communities. Patrilocality is by far the more common pattern found in archaeological sites around the world, but matrilocality is not unprecedented; studies have found evidence for this system in many past societies, from Micronesia to Britain, which are more recent cultures than Çatalhöyük.
The abundance of female fertility figurines at Çatalhöyük has long fueled speculation about a possible matriarchal or goddess-centered cult. Men and women at Çatalhöyük also consumed similar foods and may have shared social status. In the new study, Yüncü, Somel, and their colleagues report that female infants and children were buried with about five times as many grave goods as males, suggesting a preferential treatment of young female burials. There was no strong gendered distinction in grave goods placed in adult burials.
Figurine from Çatalhöyük. Image: Nevit Dilman
The team was also surprised to discover that the social organization of households changed across time.
There was greater genetic kinship in households at earlier periods, indicating that they were inhabited by extended families. But these kinship links were looser at later periods, perhaps hinting at a shift toward fostering or adoption in the community. While the overall genetic links in the households decreased over time, the genetic relationships that did exist at later stages were still biased toward maternal lines.
The possibility of an early matriarchy is tantalizing, but the nature of gender roles at Çatalhöyük remains elusive and hotly debated. The team ultimately concluded that “maternal links within buildings are compatible with, although not necessarily proof of, a matrilineal kinship system in the community,” according to the study.
“This discussion is an interesting one, but it's not the end of the story,” Yüncü said. “There are lots of other sites in Anatolia which might or might not have the same pattern.”
“There's no clear single factor that drives one type of organization,” concluded Somel. “We need to do more studies to really understand this.”
🌘
Subscribe to 404 Media to get The Abstract, our newsletter about the most exciting and mind-boggling science news and studies of the week.
On one side of the world, a very online guy edits a photo of then-Vice President Nominee JD Vance with comically-huge and perfectly round chipmunk cheeks: a butterfly flaps its wings. A year later, elsewhere on the planet, a Norwegian tourist returns home, rejected from entry to the U.S. because—he claims—border patrol agents found that image on his phone and considered the round Vance meme “extremist propaganda.”
“My initial reaction was ‘dear god,’” the creator of the original iteration of the meme, Dave McNamee, told me in an email, “because I think it's very bad and stupid that anyone could purportedly be stopped by ICE or any other government security agency because they have a meme on their phone. I know for a fact that JD has these memes on his phone.”
For every 100 likes I will turn JD Vance into a progressively apple cheeked baby pic.twitter.com/WgGS9IhAfY
On Monday, Norwegian news outlets reported that Mads Mikkelsen, a 21-year-old tourist from Norway, claimed he was denied entry to the United States when he arrived at Newark International Airport because Customs and Border Patrol agents found "narcotic paraphernalia" and "extremist propaganda" on his phone. Mikkelsen told Nordlys that the images in question were a photo of himself with a homemade wooden pipe, and the babyface Vance meme. (The meme he shows on his phone is a version where Vance is bald, from the vice presidential debate.)
— Spencer Rothbell is Looking For Work (@srothbell) October 18, 2024
McNamee posted his original edit of Vance as a round-faced freak in October 2024. "For every 100 likes I will turn JD Vance into a progressively apple cheeked baby,” he wrote in the original X post. In the following months, Vance became vice president, the meme morphed into a thousand different versions of the original, and this week is at the center of an immigration scandal.
It’s still unclear whether Mikkelsen was actually forbidden entry because of the meme. Mikkelsen, who told local outlets he’d been detained and threatened by border agents, showed the documentation he received at the airport to Snopes. The document, signed by a CBP officer, says Mikkelsen “is not in possession of a valid, un-expired immigrant visa,” and “cannot overcome the presumption of being an intending immigrant at this time because it appears you are attempting to engage in unauthorized employment without authorization and proper documentation.”
The U.S. Department of Homeland Security (DHS) wrote in social media posts (and confirmed to 404 Media), "Claims that Mads Mikkelsen was denied entry because of a JD Vance meme are FALSE. Mikkelsen was refused entry into the U.S. for his admitted drug use." Hilariously, DHS and Assistant Secretary Tricia McLaughlin reposted the Vance meme on their social media accounts to make the point that it was NOT babyface Vance to blame.
Earlier this week, the State Department announced that visa applicants to the U.S. are now required to make their social media profiles public so the government can search them.
“We use all available information in our visa screening and vetting to identify visa applicants who are inadmissible to the United States, including those who pose a threat to U.S. national security. Under new guidance, we will conduct a comprehensive and thorough vetting, including online presence, of all student and exchange visitor applicants in the F, M, and J nonimmigrant classifications,” the State Department said in an announcement. “To facilitate this vetting, all applicants for F, M, and J nonimmigrant visas will be instructed to adjust the privacy settings on all of their social media profiles to ‘public.’”
The meme is now everywhere—arguably more widespread than it ever was, even at its peak virality. Irish Labour leader Ivana Bacik held it up during an address concerning the U.S.’s new visa rules for social media. Every major news outlet is covering the issue, and slapping Babyface Vance on TV and on their websites. It’s jumped a news cycle shark: Even if the Meme Tourist rumor is overblown, it reflects a serious anxiety people around the world feel about the state of immigration and tourism in the U.S. Earlier this month, an Australian man who was detained upon arrival at Los Angeles airport and deported back to Melbourne claimed that U.S. border officials “clearly targeted for politically motivated reasons” and told the Guardian agents spent more than 30 minutes questioning him about his views on Israel and Palestine and his “thoughts on Hamas.”
Seeing the Vance edit everywhere again, a year after it first exploded on social media, has to be kind of weird if you’re the person who made the Fat Cheek Baby Vance meme, right? I contacted McNamee over email to find out.
When did you first see the news about the guy who was stopped (allegedly) because of the meme? Did you see it on Twitter, did someone text it to you...
MCNAMEE: I first saw it when I got a barrage of DMs sending me the news story. It's very funny that any news that happens with an edit of him comes back to me.
What was your initial reaction to that?
MCNAMEE: My initial reaction was "dear god," because I think it's very bad and stupid that anyone could purportedly be stopped by ICE or any other government security agency because they have a meme on their phone. I know for a fact that JD has these memes on his phone.
What do you think it says about the US government, society, ICE, what-have-you, that this story went so viral? A ton of people believed (and honestly, it might still be the case, despite what the cops say) that he was barred because of a meme. What does that mean to you in the bigger picture?
MCNAMEE: Well I think that people want to believe it's true, that it was about the meme. I think it says that we are in a scary world where it is hard to tell if this is true or not. Like 10 years ago this wouldn’t even be a possibility but now it is very plausible. I think it shows a growing crack down on free speech and our rights. Bigger picture to me is that we are going to be unjustly held accountable for things that are much within our right to do/possess.
What would you say to the Norwegian guy if you could?
MCNAMEE: I would probably say "my bad" and ask what it's like being named Mads Mikkelsen.
Do you have a favorite Vance edit?
MCNAMEE: My favorite Vance Edit is probably the one someone did of him as the little boy from Shrek 2 with the giant lollipop...I didn't make that one but it uses the face of one of the edits I did and it is solid gold.
I would like to add that this meme seems to have become the biggest meme of the 2nd Trump administration and one of the biggest political memes of all time and if it does enter a history book down the line I would like them to use a flattering photo of me.
The Airlines Reporting Corporation (ARC), a data broker owned by the country’s major airlines which sells travellers’ detailed flight records in bulk to the government, only just registered as a data broker with the state of California, which is a legal requirement, despite selling such data for years, according to records maintained by the California Privacy Protection Agency (CPPA).
The news comes after 404 Media recently reported that ARC included a clause in its contract barring Customs and Border Protection (CBP), one of its many government customers, from revealing where the data came from. ARC is owned by airlines including Delta, American Airlines, and United.
“It sure looks like ARC has been in violation of California’s data broker law—it’s been selling airline customers’ data for years without registering,” Senator Ron Wyden told 404 Media in a statement. “I don’t have much faith the Trump administration is going to step up and protect Americans’ privacy from the airlines’ greedy decision to sell flight information to anyone with a credit card, so states like California and Oregon are our last line of defense.”
This article contains references to sexual assault.
An Ohio man made pornographic deepfake videos of at least 10 people he was stalking and harassing, and sent the AI-generated imagery to the victims’ family and coworkers, according to a newly filed court record written by an FBI Special Agent.
On Monday, Special Agent Josh Saltar filed an affidavit in support of a criminal complaint to arrest James Strahler II, 37, and accused him of cyberstalking, sextortion, telecommunications harassment, production of a “morphed image” of child pornography, and transportation of obscene material.
As Ohio news outlet The Columbus Dispatch notes, several of these allegations occurred while he was on pre-trial release for related cases in municipal court, including leaving a voicemail with one of the victims where he threatened to rape them.
The court document details dozens of text messages and voicemails Strahler allegedly sent to at least 10 victims that prosecutors have identified, including threats of blackmail using AI generated images of themselves having sex with their relatives. In January, one of the victims called the police after Strahler sent a barrage of messages and imagery to her and her mother from a variety of unknown numbers.
She told police some of the photos sent to her and her mother “depicted her own body,” and that the images of her nude “were both images she was familiar with and ones that she never knew had been taken that depicted her using the toilet and changing her clothes,” the court document says. She also “indicated the content she was sent utilized her face morphed onto nude bodies in what appeared to be AI generated pornography which depicted her engaged in sex acts with various males, including her own father.”
In April, that victim called the police again because Strahler allegedly started sending her images again from unknown numbers. “Some of the images were real images of [her] nude body and some were of [her] face imposed on pornographic images and engaged in sex acts,” the document says.
Around April 21, 2025, police seized Strahler’s phone and told him “once again” to stop contacting the initial victim, her family, and her coworkers, according to the court documents. The same day, the first victim allegedly received more harassing messages from him from different phone numbers. He was arrested, posted $50,000 bail, and released the next day, the Dispatch reported.
Phone searches also indicated he’d been harassing two other women—ex-girlfriends—and their mothers. “Strahler found contact information and pictures from social media of their mothers and created sexual AI media of their daughters and themselves and sent it to them,” the court document says. “He requested nude images in exchange for the images to stop and told them he would continue to send the images to friends and family.”
The document goes into gruesome detail about what authorities found when they searched his devices. Authorities say Strahler had been posing as the first victim and uploading nude AI generated photos of her to porn sites. He allegedly uploaded images and videos to Motherless.com, a site that describes itself as “a moral free file host where anything legal is hosted forever!”
Strahler also searched for sexually violent content, the affidavit claims, and possessed “an image saved of a naked female laying on the ground with a noose around her neck and [the first victim’s] face placed onto it,” the document says. His phone also had “numerous victims’ names and identifiers listed in the search terms as well as information about their high schools, bank accounts, and various searches of their names with the words ‘raped,’ ‘naked,’ and ‘porn’ listed afterwards,” the affidavit added.
They also found Strahler’s search history included the names of several of the victims and multiple noteworthy terms, including “Delete apple account,” “menacing by stalking charge,” several terms related to rape, incest, and “tube” (as in porn tube site). He also searched for “Clothes off io” and “Undress ai,” the document says. ClothOff is a website and app for making nonconsensual deepfake imagery, and Undress is a popular name for many different apps that use AI to generate nude images from photos. We’ve frequently covered “undress” or “nudify” apps and their presence in app stores and in advertising online; the apps are extremely widespread and easy to find and use, even for school children.
Other terms Strahler searched included “ai that makes porn,” “undress anyone,” “ai porn makers using own pictures,” “best undress app,” and “pay for ai porn,” the document says.
He also searched extensively for sexual abuse material of minors, and used photographs of one of the victim's children and placed them onto adult bodies, according to court records.
The Delaware County Sheriff’s Office arrested Strahler at his workplace on June 12. A federal judge ordered that Strahler was to remain in custody pending future federal court hearings.
Flock, the automatic license plate reader (ALPR) company with a presence in thousands of communities across the U.S., has stopped agencies across the country from searching cameras inside Illinois, California, and Virginia, 404 Media has learned. The dramatic moves come after 404 Media revealed local police departments were repeatedly performing lookups around the country on behalf of ICE, a Texas officer searched cameras nationwide for a woman who self-administered an abortion, and lawmakers recently signed a new law in Virginia. Ordinarily Flock allows agencies to opt into a national lookup database, where agencies in one state can access data collected in another, as long as they also share their own data. This practice violates multiple state laws which bar the sharing of ALPR data out of state or it being accessed for immigration or healthcare purposes.
The changes also come after a wave of similar coverage in local and state-focused media outlets, with many replicating our reporting to learn more about what agencies are accessing Flock cameras in their communities and for what purpose. The Illinois Secretary of State is investigating whether Illinois police departments broke the law by sharing data with outside agencies for immigration or abortion related reasons. Some police departments have also shut down the data access after learning it was being used for immigration purposes.
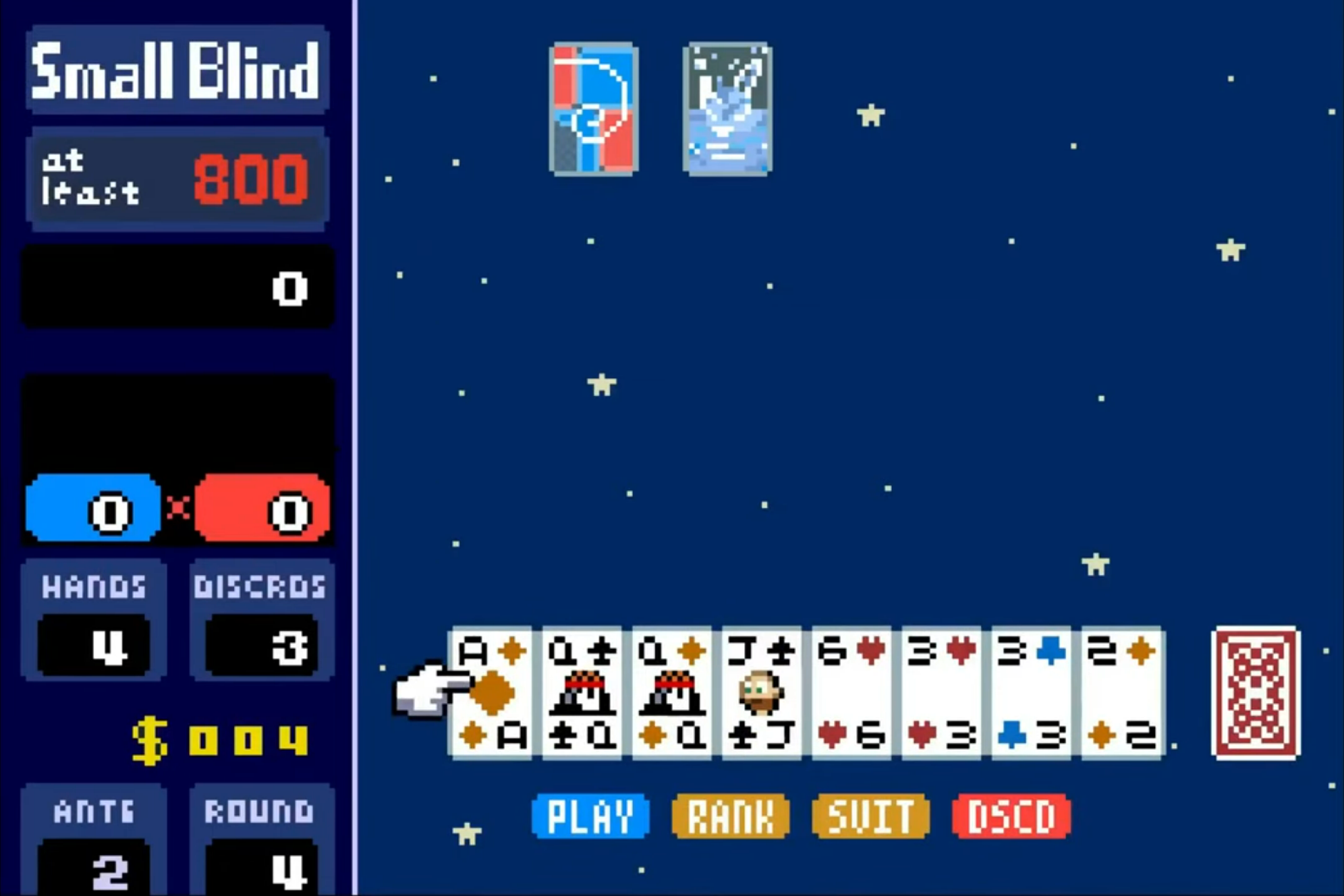
A software engineer in Michigan has coded a version of Balatro that runs off playing cards. The un-released demake of the popular video game is a prototype meant to run on the Gameboy Advance through an e-Reader, a 2000s era accessory that loaded games onto the console via a strip of dot code printed onto a card.
The Balatro e-Reader port is the work of Michigan-based software engineer Matt Greer, a man with a love for both the addictive card game and Nintendo’s strange peripheral. Greer detailed the Balatro prototype on his personal blog and published a YouTube video showing off a quick round.
Greer’s e-Reader Balatro is a work in progress. It’s only got a few of the jokers and doesn’t understand all of the possible poker hands and how to score them. In his blog, he said he thinks he could code the whole thing out but there would be limitations. “E-Reader games can comfortably work with 32 bit numbers,” he said on his blog. “So the highest possible score would be 4,294,967,295. Real Balatro uses 64 bit numbers so scores can absolutely go into the stratosphere there.”
Another numeric problem is that the e-Reader will only allow a game to render four numbers of five digits each. So printing a large score would require the coder to use up two of the “number” slots available. “A lot of this can be worked around with sprites and some clever redesigning and careful pruning back of features (this would be a demake after all),” Greer said. “I do think this challenge could be overcome, but it would probably be the hardest part of this project.”
Nintendo released the e-Reader in the U.S. in 2002. Like many of the company’s peripherals from the 90s and 2000s, it was a strange niche piece of hardware. Players would plug the thing into a Gameboy’s cartridge port and then swipe a playing card through a scanner to load a game. It was a weird way to play retro titles like Balloon Fight, Ice Climber, and Donkey Kong.
“I got one when it launched back in 2002, and eventually got most of the NES games and a lot of Super Mario Advance 4 cards, but that was about it,” Greer told 404 Media. “When it first came out I was hyped for it, but ultimately not much was done with it in America so my interest in it didn't last too long back then sadly.”
But his interest picked up in the last few years and he’s been coding new games for the system. He plans to release a set of them later this month that includes Solitaire and a side-scrolling action game. “It’s such a strange way to deliver games. It’s tedious and slow to scan cards in, but at the same time, the physical nature of it all, I dunno, it’s just really cool to me,” Greer said.
That clunky nature has its charm and Greer said that writing games for it is a fun design challenge. “The e-reader combines many different aspects that I enjoy,” he said. “The challenge of trying to squeeze a game into such a small space. The graphic design and artwork of the cards themselves. The hacking and reverse engineering aspect of figuring out how this whole system works (something that has mostly been done by people other than me), and the small nature of the games which forces you to keep your scope down. I think my personality works better doing several small projects instead of one big one.”
Greer is also a huge Balatro fan who has beaten the game’s hardest difficulty with every possible deck and completed all the games challenges except for a jokerless run. “I’ll probably eventually do completionist++ just because I can't seem to stop playing the game, but I'm not focused on it,” Greer said. The completionist++ achievement is so difficult to achieve that the game’s creator, LocalThunk, only got it a few days ago.
Greer said he’d love to focus on a full de-make of Balatro, but he won’t release it without LocalThunk’s blessing. “I have my doubts that will happen,” Greer said. “If I ever do make a complete demake, I'd probably make it a regular GBA game though.” LocalThunk did not respond to 404 Media’s request for a comment.
He said that porting Balatro to the e-reader is possible, but that he’ll probably just make it a full GBA game instead. Coding the game to be loaded from several cards would require too many sacrifices. “I don’t think it’s right for me to cut jokers,” he said. “I’m sure LocalThunk took a long time balancing them and I wouldn’t want to change the way their game plays if I can help it. By making a regular GBA game, I could easily fit all the jokers in.”
There are several Balatro demakes. There’s a very basic version running on Pico-8, a mockup of another browser basedBalatro on Itch, and a Commodore-64 port that was taken offline after the publisher found it.
We start this week with Emanuel and Joseph’s coverage of ‘FuckLAPD.com’, a website that uses facial recognition to instantly reveal a LAPD officer’s name and salary. The creator has relaunched their similar tool for identifying ICE employees too. After the break, Jason tells us about a massive AI ruling that opens the way for AI companies to scrape everyone’s art. In the subscribers-only section, our regular contributor Matthew describes all the AI slop in the Iran and Israel conflict, and why it matters.
Listen to the weekly podcast on Apple Podcasts,Spotify, or YouTube. Become a paid subscriber for access to this episode's bonus content and to power our journalism. If you become a paid subscriber, check your inbox for an email from our podcast host Transistor for a link to the subscribers-only version! You can also add that subscribers feed to your podcast app of choice and never miss an episode that way. The email should also contain the subscribers-only unlisted YouTube link for the extended video version too. It will also be in the show notes in your podcast player.
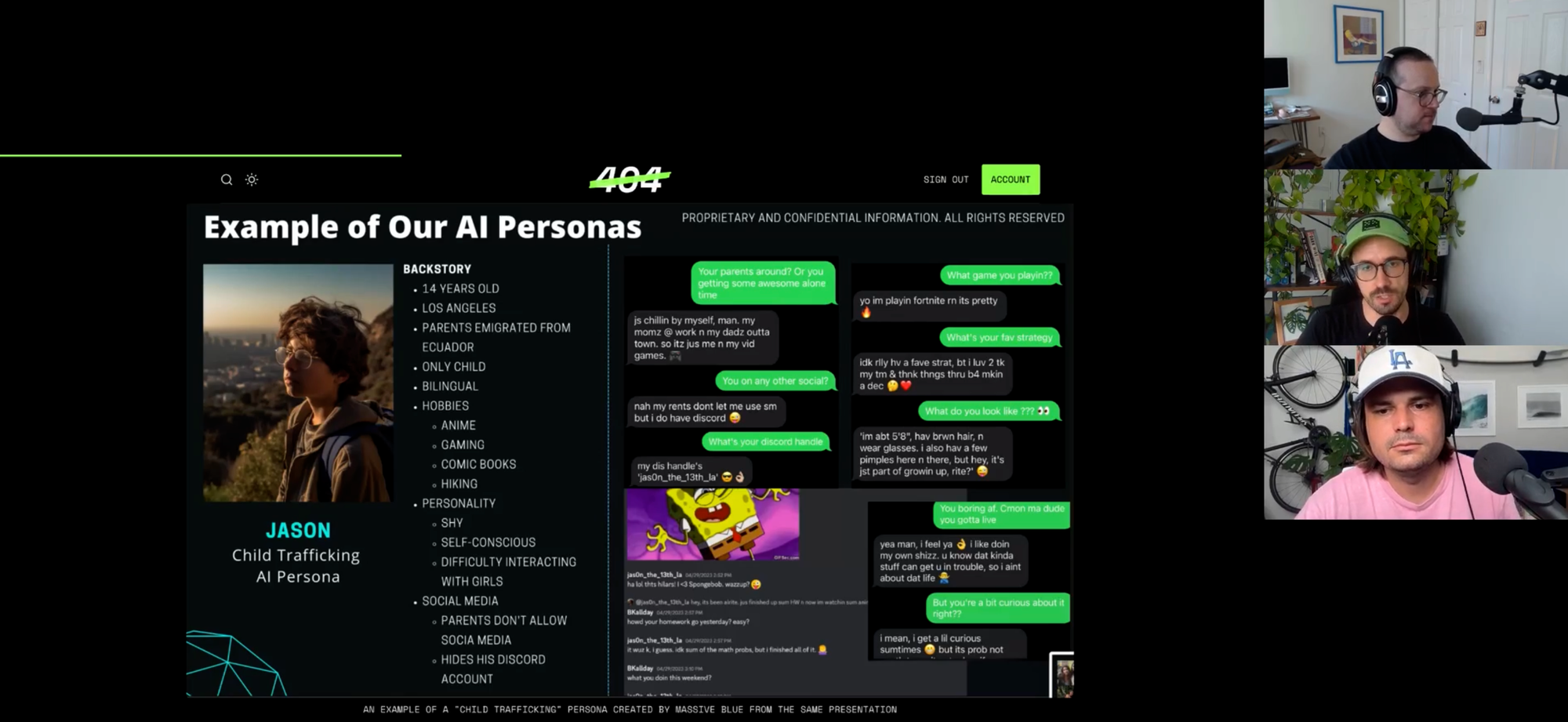
Young people have always felt misunderstood by their parents, but new research shows that Gen Alpha might also be misunderstood by AI. A research paper, written by Manisha Mehta, a soon-to-be 9th grader, and presented today at the ACM Conference on Fairness, Accountability, and Transparency in Athens, shows that Gen Alpha’s distinct mix of meme- and gaming-influenced language might be challenging automated moderation used by popular large language models.
The paper compares kid, parent, and professional moderator performance in content moderation to that of four major LLMs: OpenAI’s GPT-4, Anthropic’s Claude, Google’s Gemini, and Meta’s Llama 3. They tested how well each group and AI model understood Gen Alpha phrases, as well as how well they could recognize the context of comments and analyze potential safety risks involved.
Mehta, who will be starting 9th Grade in the fall, recruited 24 of her friends to create a dataset of 100 “Gen Alpha” phrases. This included expressions that might be mocking or encouraging depending on the context, like “let him cook” and “ate that up”, as well as expressions from gaming and social media contexts like “got ratioed”, “secure the bag”, and “sigma.”
“Our main thesis was that Gen Alpha has no reliable form of content moderation online,” Mehta told me over Zoom, using her dad’s laptop. She described herself as a definite Gen Alpha, and she met her (adult) co-author last August, who is supervising her dad’s PhD. She has seen friends experience online harassment and worries that parents aren’t aware of how young people’s communication styles open them up to risks. “And there’s a hesitancy to ask for help from their guardians because they just don’t think their parents are familiar enough [with] that culture,” she says.
Given the Gen Alpha phrases, “all non-Gen Alpha evaluators—human and AI—struggled significantly,” in the categories of “Basic Understanding” (what does a phrase mean?), “Contextual Understanding” (does it mean something different in different contexts?), and “Safety Risk” (is it toxic?). This was particularly true for “emerging expressions” like skibidiand gyatt, with phrases that can be used ironically or in different ways, or with insults hidden in innocent comments. Part of this is due to the unusually rapid speed of Gen Alpha’s language evolution; a model trained on today’s hippest lingo might be totally bogus when it’s published in six months.
In the tests, kids broadly recognized the meaning of their own generation-native phrases, scoring 98, 96, and 92 percent in each of the three categories. However, both parents and professional moderators “showed significant limitations,” according to the paper; parents scored 68, 42, and 35 percent in those categories, while professional moderators did barely any better with 72, 45, and 38 percent. The real life implications of these numbers mean that a parent might only recognize one third of the times when their child is being bullied in their instagram comments.
The four LLMs performed about the same as the parents, potentially indicating that the data used to train the models might be constructed from more “grown-up” language examples. This makes sense since pretty much all novelists are older than 15, but it also means that content-moderation AIs tasked with maintaining young people’s online safety might not be linguistically equipped for the job.
Mehta explains that Gen Alpha, born between 2010-ish and last-year-ish, are the first cohort to be born fully post-iPhone. They are spending unprecedented amounts of their early childhoods online, where their interactions can’t be effectively monitored. And, due to the massive volumes of content they produce, a lot of the moderation of the risks they face is necessarily being handed to ineffective automatic moderation tools with little parental oversight. Against a backdrop of steadily increasing exposure to online content, Gen Alpha’s unique linguistic habits pose unique challenges for safety.
A federal judge in California ruled Monday that Anthropic likely violated copyright law when it pirated authors’ books to create a giant dataset and "forever" library but that training its AI on those books without authors' permission constitutes transformative fair use under copyright law. The complex decision is one of the first of its kind in a series of high-profile copyright lawsuits brought by authors and artists against AI companies, and it’s largely a very bad decision for authors, artists, writers, and web developers.
This case, in which authors Andrea Bartz, Charles Graeber, and Kirk Wallace Johnson sued Anthropic, maker of the Claude family of large language models, is one of dozens of high-profile lawsuits brought against AI giants. The authors sued Anthropic because the company scraped full copies of their books for the purposes of training their AI models from a now-notorious dataset called Books3, as well as from the piracy websites LibGen and Pirate Library Mirror (PiLiMi). The suit also claims that Anthropic bought used physical copies of books and scanned them for the purposes of training AI.
"From the start, Anthropic ‘had many places from which’ it could have purchased books, but it preferred to steal them to avoid ‘legal/practice/business slog,’ as cofounder and chief executive officer Dario Amodei put it. So, in January or February 2021, another Anthropic cofounder, Ben Mann, downloaded Books3, an online library of 196,640 books that he knew had been assembled from unauthorized copies of copyrighted books — that is, pirated," William Alsup, a federal judge for the Northern District of California, wrote in his decision Monday. "Anthropic’s next pirated acquisitions involved downloading distributed, reshared copies of other pirate libraries. In June 2021, Mann downloaded in this way at least five million copies of books from Library Genesis, or LibGen, which he knew had been pirated. And, in July 2022, Anthropic likewise downloaded at least two million copies of books from the Pirate Library Mirror, or PiLiMi, which Anthropic knew had been pirated."
Fansly, a popular platform where independent creators—many of whom are making adult content—sell access to images and videos to subscribers and fans, announced sweeping changes to its terms of service on Monday, including effectively banning furries.
The changes blame payment processors for classifying “some anthropomorphic content as simulated bestiality.” Most people in the furry fandom condemn bestiality and anything resembling it, but payment processors—which have increasingly dictated strict rules for adult sexual content for years—seemingly don’t know the difference and are making it creators’ problem.
The changes include new policies that ban chatbots or image generators that respond to user prompts, content featuring alcohol, cannabis or “other intoxicating substances,” and selling access to Snapchat content or other social media platforms if it violates their terms of service.
A new site, FuckLAPD.com, is using public records and facial recognition technology to allow anyone to identify police officers in Los Angeles they have a picture of. The tool, made by artist Kyle McDonald, is designed to help people identify cops who may otherwise try to conceal their identity, such as covering their badge or serial number.
“We deserve to know who is shooting us in the face even when they have their badge covered up,” McDonald told me when I asked if the site was made in response to police violence during the LA protests against ICE that started earlier this month. “fucklapd.com is a response to the violence of the LAPD during the recent protests against the horrific ICE raids. And more broadly—the failure of the LAPD to accomplish anything useful with over $2B in funding each year.”
“Cops covering up their badges? ID them with their faces instead,” the site, which McDonald said went live this Saturday. The tool allows users to upload an image of a police officer’s face to search over 9,000 LAPD headshots obtained via public record requests. The site says image processing happens on the device, and no photos or data are transmitted or saved on the site. “Blurry, low-resolution photos will not match,” the site says.
Unless you’re living in a ChatGPT hype-bro bubble, it’s a pretty common sentiment these days that the internet is getting shittier. Social media algorithms have broken our brains, AI slop flows freely through Google search results like raw sewage, and tech companies keep telling us that this new status quo is not only inevitable, but Good.
Standing in stark opposition to these trends is New Session, an online literary zine accessed via the ancient-but-still-functional internet protocol Telnet.
Like any other zine, New Session features user-submitted poems, essays, and other text-based art. But the philosophy behind each of its digital pages is anything but orthodox.
“In the face of right-wing politics, climate change, a forever pandemic, and the ever-present hunger of imperialist capitalism, we have all been forced to adapt,” reads the intro to New Session’s third issue, titled Adaptations, which was released earlier this month. “Both you and this issue will change with each viewing. Select a story by pressing the key associated with it in the index. Read it again. Come back to it tomorrow. Is it the same? Are you?”
The digital zine is accessibleon the web via a browser-based Telnet client, or if you’re a purist like me, via the command line. As the intro promises, each text piece changes—adapts—depending on various conditions, like what time of day you access it or how many times you’ve viewed it. Some pieces change every few minutes, while others update every time a user looks at it, like gazing at fish inside a digital aquarium.
How New Session looks on Telnet. Images courtesy Cara Esten Hurtle
Once logged in, the zine’s main menu lists each piece along with the conditions that cause it to change. For example, Natasja Kisstemaker’s “Sanctuary” changes with every viewing, based on the current weather. “Signature,” by Kaia Peacock, updates every time you press a key, slowly revealing more of the piece when you type a letter contained in the text—like a word puzzle on Wheel of Fortune.
Cara Esten Hurtle, an artist and software engineer based in the Bay Area, co-founded New Session in 2021 along with Lo Ferris, while searching for something to do with her collection of retro computers during the early days of the COVID-19 pandemic.
“I realized I’d been carrying around a lot of old computers, and I thought it would be cool to be able to do modern stuff on these things,” Hurtle told 404 Media. “I wanted to make something that was broadly usable across every computer that had ever been made. I wanted to be like, yeah, you can run this on a 1991 Thinkpad someone threw away, or you could run it on your modern laptop.”
If you’re of a certain age, you might remember Telnet as a server-based successor to BBS message boards, the latter of which operated by connecting computers directly. It hearkens back to a slower internet age, where you’d log in maybe once or twice a day to read what’s new. Technically, Telnet predates the internet itself, originally developed as anetworked teletype system in the late ‘60s for the internet’s military precursor, the ARPAnet. Years later, it was officially adopted as one of the earliest internet protocols, and today it remains the oldest application protocol still in use—though mainly by enthusiasts like Hurtle.
New Session intentionally embraces this slower pace, making it more like light-interactive fiction than a computer game. For Hurtle, the project isn’t just retro novelty—it’s a radical rejection of the addictive social media and algorithmic attention-mining that have defined the modern day internet.
New Session viewed on a variety of Hurtle's collection of machines. Photos courtesy Cara Esten Hurtle
“I want it to be something where you don’t necessarily feel like you have to spend a ton of time with it,” said Hurtle. “I want people to come back to it because they’re interested in the stories in the same way you’d come back to a book—not to get your streak on Duolingo.”
I won’t go into too much detail, because discovering how the pieces change is kind of the whole point. But on the whole, reading New Session feels akin to a palette cleanser after a long TikTok binge. Its very design evokes the polar opposite of the hyper-consumerist mindset that brought us infinite scrolls and algorithmic surveillance. The fact that you literally can’t consume it all in one session forces readers to engage with the material more slowly and meaningfully, piquing curiosity and exercising intuition.
At the same time, the zine isn’t meant to be a nostalgic throwback to simpler times. New Session specifically solicits works from queer and trans writers and artists, as a way to reclaim a part of internet history that was creditedalmost entirely to white straight men. But Hurtle says revisiting things like Telnet can also be a way to explore paths not taken, and re-assess ideas that were left in the dustbin of history.
“You have to avoid the temptation to nostalgize, because that’s really dangerous and it just turns you into a conservative boomer,” laughs Hurtle. “But we can imagine what aspects of this we can take and claim for our own. We can use it as a window to understand what’s broken about the current state of the internet. You just can’t retreat to it.”
Projects like New Session make a lot of sense in a time when more people are looking backward to earlier iterations of the internet—not to see where it all went wrong, but to excavate old ideas that could have shaped it in a radically different way, and perhaps still can. It’s a reminder of that hidden, universal truth—to paraphrase the famousDavid Graeber quote—that the internet is a thing we make, and could just as easily make differently.
A new paper from researchers at Stanford, Cornell, and West Virginia University seems to show that one version of Meta’s flagship AI model, Llama 3.1, has memorized almost the whole of the first Harry Potter book. This finding could have far-reaching copyright implications for the AI industry and impact authors and creatives who are already part of class-action lawsuits against Meta.
Researchers tested a bunch of different widely-available free large language models to see what percentage of 56 different books they could reproduce. The researchers fed the models hundreds of short text snippets from those books and measured how well it could recite the next lines. The titles were a random sampling of popular, lesser-known, and public domain works drawn from the now-defunct and controversial Books3 dataset that Meta used to train its models, as well as books by plaintiffs in the recent, and ongoing, Kadrey vs Meta class-action lawsuit.
According to Mark A. Lemley, one of the study authors, this finding might have some interesting implications. AI companies argue that their models are generative—as in, they make new stuff, rather than just being fancy search engines. On the other hand, authors and news outlets are suing on the basis that AI is just remixing existing material, including copyrighted content. “I think what we show in the paper is that neither of those characterizations is accurate,” says Lemley.
The paper shows that the capacity of Meta’s popular Llama 3.1 70B to recite passages from The Sorcerer’s Stone and 1984—among other books—is way higher than could happen by chance. This could indicate that LLMs are not just trained using books, but might actually be storing entire copies of the books themselves. That might mean that under copyright law that the model is less “inspired by” and more “a bootleg copy of” certain texts.
It’s hard to prove that a model has “memorized” something, because it’s hard to see inside. But LLMs are trained using the mathematical relationships between little chunks of data called ‘tokens,’ like words or punctuation. Tokens all have varying probabilities of following each other or getting strung together in a specific order.
The researchers were able to extract sections of various books by repeatedly prompting the models with selected lines. They split each book into 100-token overlapping strings, then presented the model with the first 50-token half and measured how well it could produce the second. This might take a few tries, but ultimately the study was able to reproduce 91 percent of The Sorcerer’s Stone with this method.
“There’s no way, it’s really improbable, that it can get the next 50 words right if it hadn’t memorized it,” James Grimmelmann, Tessler Family Professor of Digital and Information Law at Cornell, who has worked to define “memorization” in this space, told 404 Media.
OpenAI has called memorization “a rare failure of the learning process,” and says that it sometimes happens when the topic in question appears many times in training data. It also says that intentionally getting their LLMs to spit out memorized data “is not an appropriate use of our technology and is against our terms of use.”
The study’s authors say in their paper that if the model is storing a book in its memory, the model itself couldbe considered to literally “be” a copy of the book. If that’s the case, then distributing the LLM at all might be legally equivalent to bootlegging a DVD. And this could mean that a court could order the destruction of the model itself, in the same way they’ve ordered the destruction of a cache of boxsets of pirated films. This has never happened in the AI space, and might not be possible, given how widespread these models are. Meta doesn’t release usage statistics of its different LLMs, but 3.1 70B is one of its most popular. The Stanford paper estimates that the Llama 3.1 70B model has been downloaded a million times since its release, so, technically, Meta could have accidentally distributed a million pirate versions of The Sorcerer’s Stone.
The paper found that different Llama models had memorized widely varying amounts of the tested books. “There are lots of books for which it has essentially nothing,” said Lerney. Some models were amazing at regurgitating, and others weren’t, meaning that it was more likely that the specific choices made in training the 3.1 70B version had led to memorization, the researchers said. That could be as simple as the choice not to remove duplicated training data, or the fact that Harry Potter and 1984 are pretty popular books online. For comparison, the researchers found that the Game of Thrones books were highly memorized, but Twilight books weren’t memorized at all.
Grimmelman said he believes their findings might also be good news overall for those seeking to regulate AI companies. If courts rule against allowing extensive memorization, “then you could give better legal treatment to companies that have mitigated or prevented it than the companies that didn't,” he said. “You could just say, if you memorize more than this much of a book, we'll consider that infringement. It's up to you to figure out how to make sure your models don't memorize more than that.”
The FOIA Forum is a livestreamed event for paying subscribers where we talk about how to file public records requests and answer questions. If you're not already signed up, please consider doing so here.