The Astronomer CEO's Coldplay Concert Fiasco Is Emblematic of Our Social Media Surveillance Dystopia

The CEO seemingly having an affair with the head of HR at his company at the Coldplay concert is a viral video for the ages, but it is also, unfortunately, emblematic of our current private surveillance and social media hellscape.
The video, which is now viral on every platform that we can possibly think of, has been covered by various news outlets, and is Pop Crave official, shows Andy Byron, the CEO of a company called Astronomer, with his arms around Astronomer’s head of HR, Kristen Cabot. The jumbotron cuts from one fan to this seemingly happy couple. They both simultaneously die inside; “Oh look at this happy couple,” Coldplay lead singer Chris Martin says. The woman covers her face and spins away. The man ducks out of frame. “Either they’re having an affair or they’re very shy,” Martin said. The camera pans to another company executive standing next to them, who is seemingly shaking out of discomfort.
It is hard to describe how viral this is at the moment, in a world in which so many awful things are occurring and in which nothing holds anyone’s attention for any length of time and in a world in which we are all living in our own siloed realities. “Andy Byron” is currently the most popular trending Google term in the United States, with more than double the searches of the next closest term.
There are so many levels to this embarrassment—the Coldplay of it all, the HR violation occurring on jumbotron, etc—that one could likely write a doctoral dissertation on this 15 second video.
But the aftermath of this video demonstrates a phenomenon that we have now seen over and over again on all of social media, but on TikTok especially: The instant, gleeful doxing of people for reasons that run the spectrum from the very bad (being a Nazi) to the utterly benign (dancing weird at a Taylor Swift concert, being a hot security guard, standing in public). “TikTok help me find him / her” is now so common that it is a meme.
404 Media doesn’t know what’s going on in Byron or Cabot’s marriages and neither does anyone else posting about it; we have zero clue what’s going on behind the scenes or what is currently occurring in the personal lives of everyone involved.
It is worth briefly considering the dystopia of this situation and its aftermath. It is not clear exactly how the Astronomer CEO was initially identified, but we have seen numerous cases where TikTok commenters and creators use Pimeyes and other readily available, often free facial recognition and social media research tools to identify a person.
The Astronomer CEO’s name, his wife’s name, the head of HR’s name, and the third company executive’s name and social media profiles are all over the TikTok comments and Reddit comments. His latest LinkedIn post was full of comments about the incident, left before he disabled comments and ultimately deleted the post. Commenters have pointed out that his wife has removed his last name from several of her social media profiles.
Polymarket’s degenerate gamblers turned the scandal into a market. The site lets users bet on events with binary outcomes like whether or not Byron will lose his job as CEO of Astronomer. A gambler pays a few cents to vote “yes” or “no” on the outcome of the event and wins the difference up to a dollar on each vote if they guessed right. Each vote shifts the odds up and down.
Today Polymarket opened two new Byron-related bets. The first asks the question: “Andy Byron out as Astronomer CEO by next Friday?” As of this writing, the site is giving him a 40 percent chance of leaving. Polymarket doesn’t care if he resigns or gets fired, the bet pays out to its “yes” voters so long as he leaves.
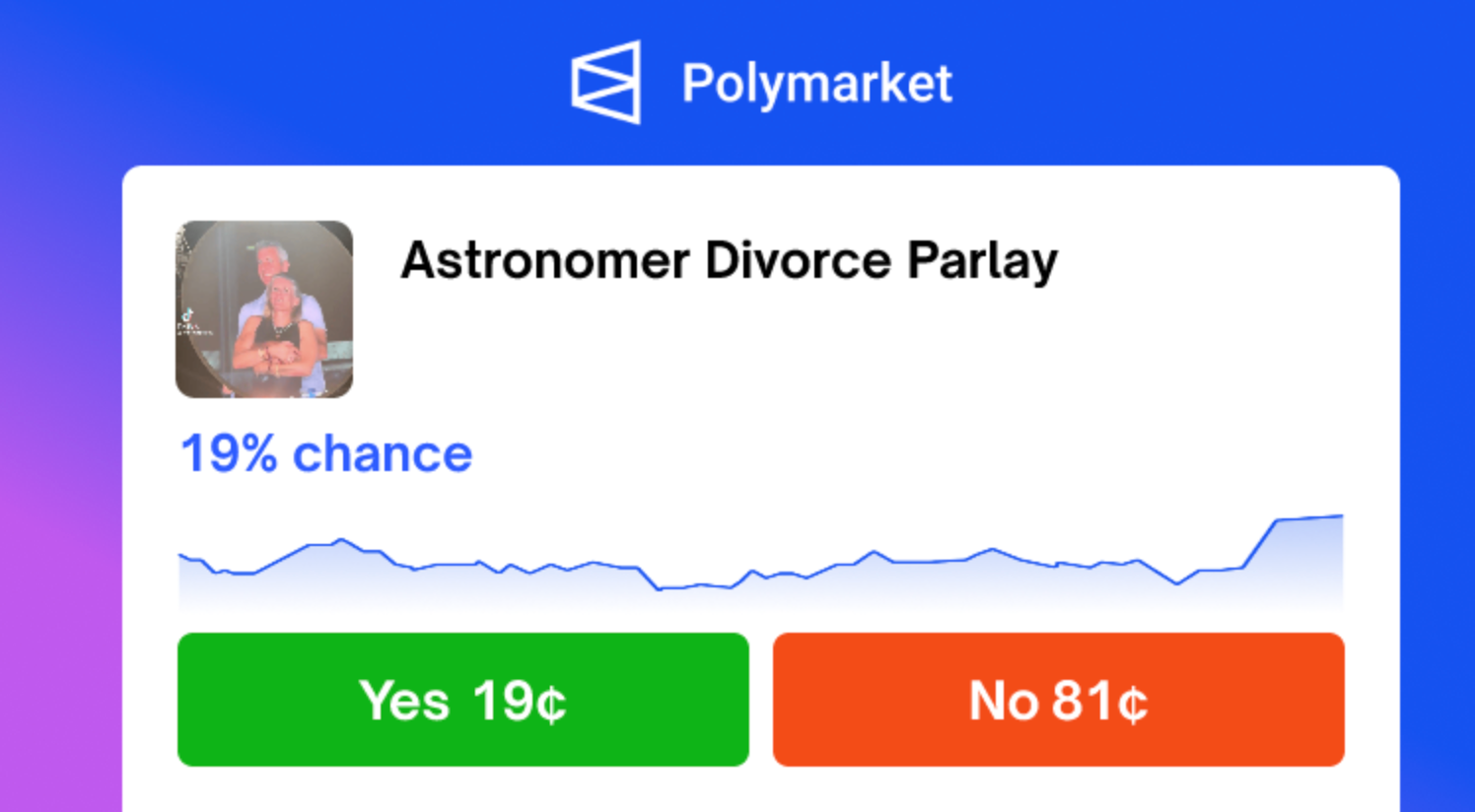
The crueler bet, and the one with more activity, is the “Astronomer Divorce Parlay.” A parlay is a series or combination of bets, and this Polymarket listing requires both Byron and Cabot to get divorced. An announcement will satisfy the bet, it doesn’t have to be an official filing. But it can come from Byron and Cabot themselves or their spouses. The image attached to the bet is a screenshot from the moment the Jumbotron filmed the couple embracing.
As of this writing, the odds are 21 percent that both couples divorce.
Polymarket’s X account got in on the action. As both of the markets opened, the account posted about Byron and Cabot four times in a row. “Smart bet?” Polymarket asked above a picture showing social media photos of the pair listed next to the current odds that they’d divorce their spouses.
Brands are using Byron and Cabot’s face to build hype. The NEON film studio posted a picture of the couple on X to promote its upcoming horror movie Together. Chipotle commented on the story with a picture of its billboard that reads “It’s OK to Cheat.” Most chilling, the NYC Department of Sanitation used the viral moment to remind everyone that it has cameras everywhere.
Scrolling through a TikTok search for “CEO of Astronomer” (a TikTok-recommended search term) is full of wannabe influencers giving their own take on the saga, greenscreening the video behind their cut out faces with titles like “CHEATING COLDPLAY AFFAIR BOSTON CONCERT COUPLE UPDATE,” and “COLDPLAY EXPUSO A DOS AMANTES.” Fox News, Buzzfeed, and other huge accounts have posted the footage more or less unedited on their own accounts. Writing this article, we understand, puts us into this exact fray.
But one does not have to have sympathy or empathy for a CEO to see how this sort of thing could and often does go off the rails. This example is emblematic of the problem specifically because it’s easy to laugh at these people and because they’re doing something distasteful, but not illegal. The same technologies used to dox and research this CEO are routinely deployed against the partners of random people who have had messy breakups, attractive security guards, people who look “suspicious” and are caught on Ring cameras by people on Nextdoor, people who dance funny in public, and so on. There has been endless debate about the ethics of doxing cops and ICE agents and Nazis, and there are many times where it makes sense to research people doing harm on behalf of the state or who are doing violent, scary things in to innocent people. It is another to deploy these technologies against random people you saw on an airplane or who had a messy breakup with an influencer. And of course, these same technologies are regularly deployed by police and the feds against undocumented immigrants, regular people, and people wanting to visit the United States on tourist visas.
“JUST IN: Astronomer CEO Andy Byron’s wife removes his last name from her Facebook profile,” a follow up post said next to a screenshot from Byron’s wife’s Facebook account. And in a reply: The odds of them both getting divorced this year are soaring. 52% chance.”